





Power Automate Desktopを使って、受信したメールの本文テキストから必要な箇所を抽出するフローを作ってみます。

メール本文の抽出したい箇所を確認する
前回からの続きで、消費者庁のリコール情報新着メールを利用して、ネット販売に活かせる情報を抜き出してみます。

※ 本ブログのRPA・自動化は、主にネット販売に活かすためのものを記事にしていますが、本記事を参考に他でも充分応用可能かと思います
消費者庁のリコール情報新着メールのメール本文は、以下のように1リコール商品につき3行で記載されています。
- 商品名
- リコールとなった理由・経緯
- リコール詳細が記載されたページのURL
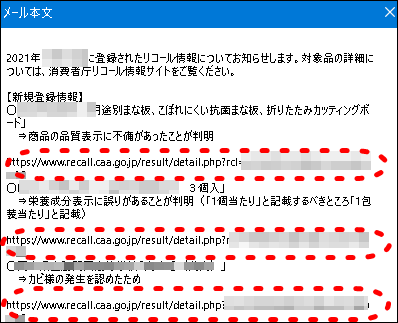
なお、記載されているURLのページにアクセスすると、以下のようなリコール情報の詳細が掲載されています。

アマゾンでの販売では、リコール対象商品は出品制限対象であり、知らずに出品しているとアカウントに悪影響を及ぼす可能性があるため、RPAで以下のような自動化をつくってみたいと考えています。
- 受信したリコール情報新着メールの本文テキスト情報を取得
- メール本文に記載されたURL(リコール商品詳細ページ)を抜き出す
- 抜き出したURLにアクセス
- リコール商品詳細ページの「JANコード:xxxxxxxxxxxxx」の箇所を取得してファイルに保存
リコール情報は平日ほぼ毎日更新されており、リコール情報の新着メールも数多く受信します。
自社の出品商品の中に、出品制限対象である「リコール対象商品」が無いか把握するためには、商品名のようにゆらぎのある情報ではなく、商品を一意で検索できるJANコードを使う方が正確で手間もかかりません(※出品商品情報にJANコードが無い・登録されていない場合は除く)
まずは、リコール新着情報のメール本文からリコール商品詳細ページのURLを抜き出すところから始めてみます。
テキストを抽出するアクションを追加する
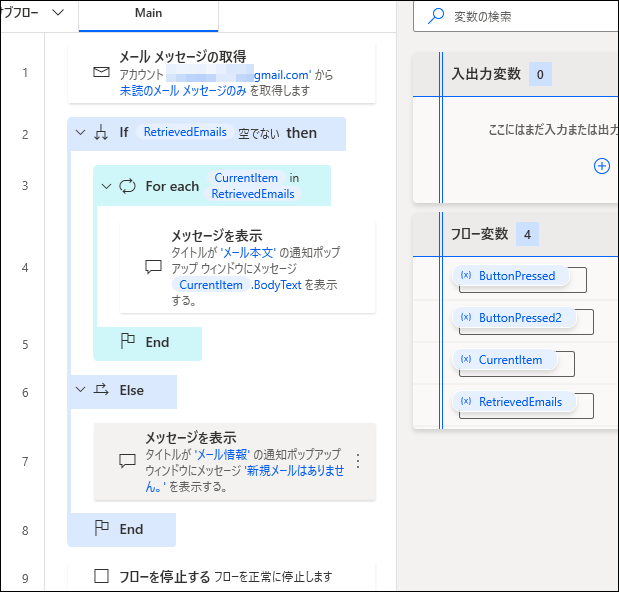
先の記事で作成済みの、メール本文テキストの取得フローにアクションを追加していきます。
- 1作成済みのメール本文テキスト取得のフローを開く

- 2抜き出すテキスト情報の事前処理(エスケープテキスト)
テキスト情報を抜き出すために正規表現(※)を利用します。今回抜き出すテキスト情報が「URL」のため、「スラッシュ(/)」や「ドット(.)」などの特殊文字が含まれており、あらかじめ事前処理(エスケープ処理)する必要があります。
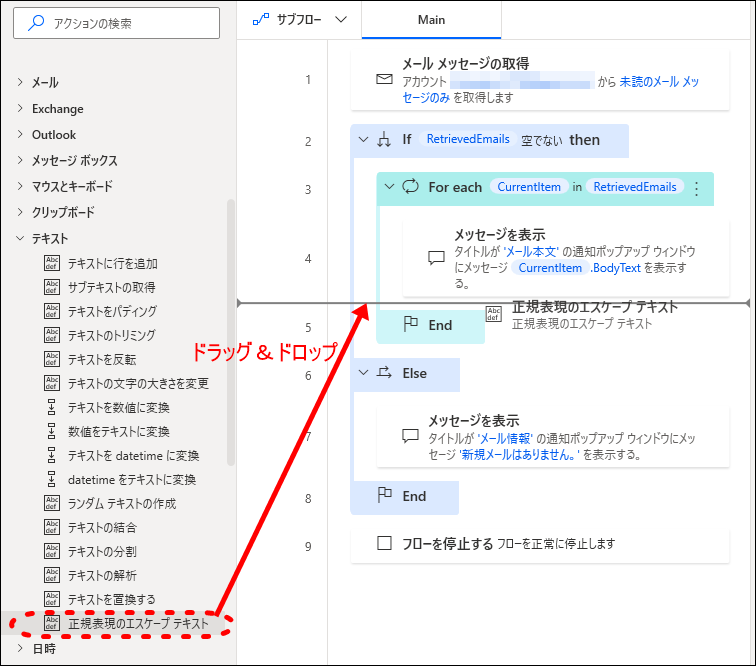
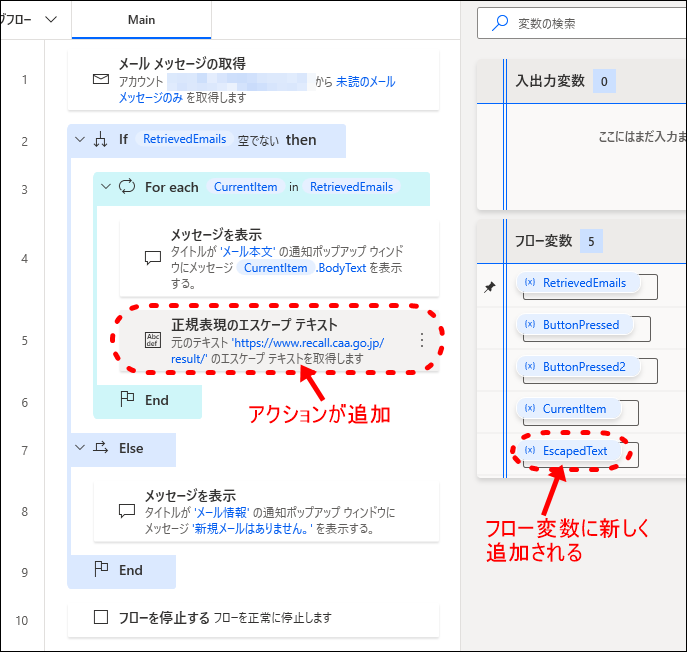
正規表現とは検索正規表現 エスケープ処理とは検索「正規表現のエスケープテキスト」アクションを、最初の「メッセージを表示」アクションのすぐ後にドラッグ&ドロップします。

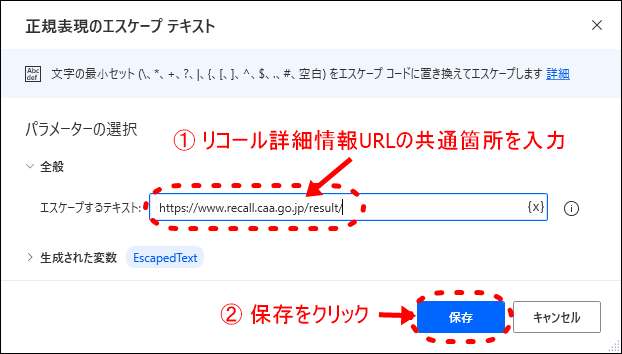
- 3エスケープするテキストを指定
設定ウィンドウがポップアップします。
今回抽出するリコール詳細情報のURLは共通で「https://www.recall.caa.go.jp/result/」で始まるURLとなります。この共通箇所となるURLを指定します。

- 4エスケープ処理のアクションが追加される
URLのエスケープ処理のアクションが追加されると同時に、エスケープ処理済みテキストが保存されるフロー変数「EscapedText」が追加されます。

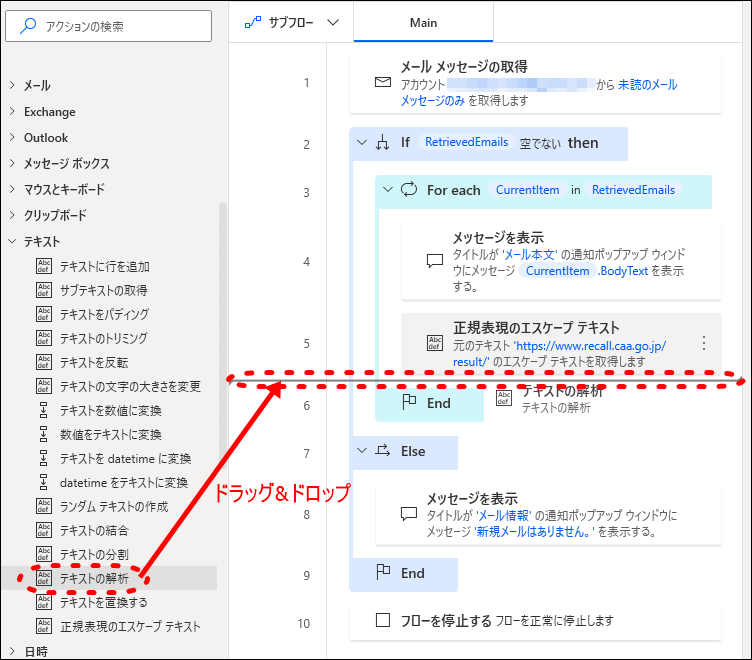
- 5「テキストの解析」アクションの追加
テキストを抽出するアクションを追加します。
「テキストの解析」アクションを「正規表現のエスケープテキスト」アクションのすぐ後にドラッグ&ドロップします。

- 6「テキストの解析」アクションの詳細設定
ポップアップが開きます。
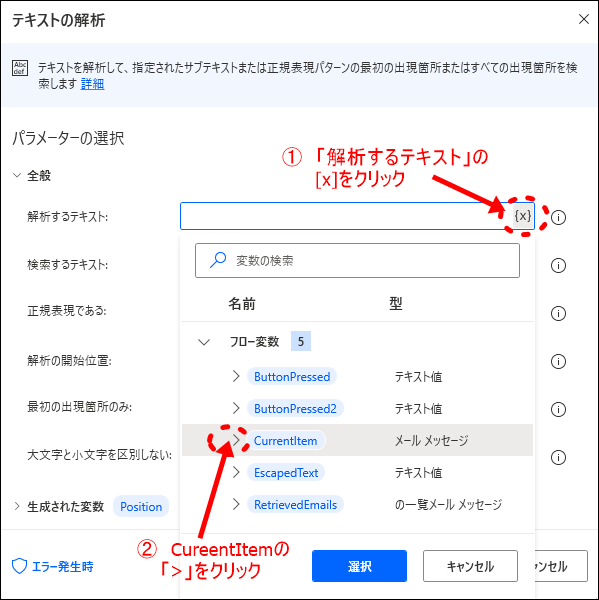
「解析するテキスト」にある[ x ]をクリックして、「CurrentItem」のプロパティを表示させます。

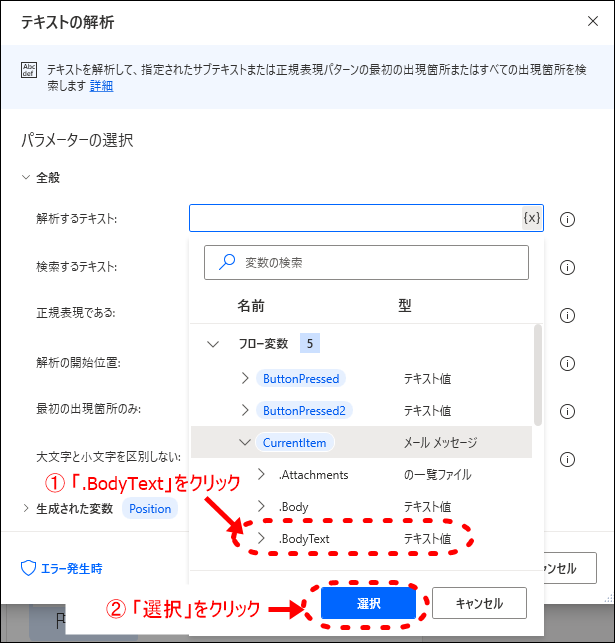
- 7解析するテキストに「CurrentItem」の「.BodyText」を選択
「解析するテキスト」にメール本文のテキスト情報が入る「CurrentItem」の「BodyText」値を選択します。

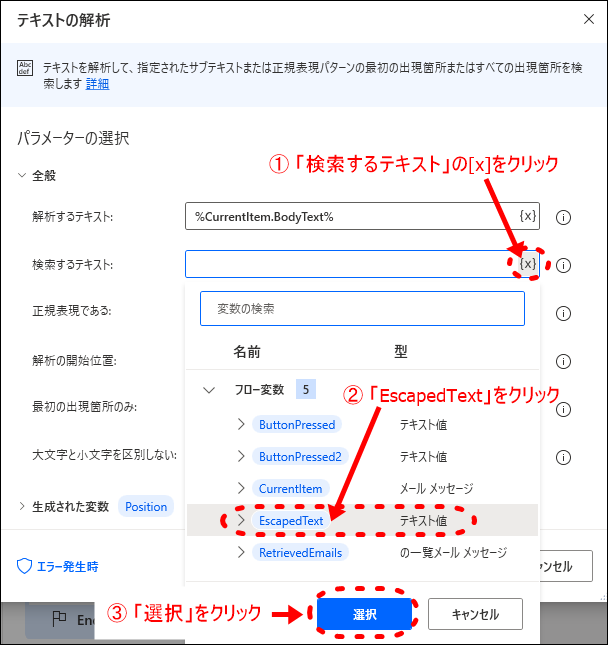
- 8「検索するテキスト」を選択する
「検索するテキスト」に、フロー変数「EscapedText」を選択します。既に「EscapedText」には「https://www.recall.caa.go.jp/result/」をエスケープ処理したものが格納されています。

- 9その他の設定
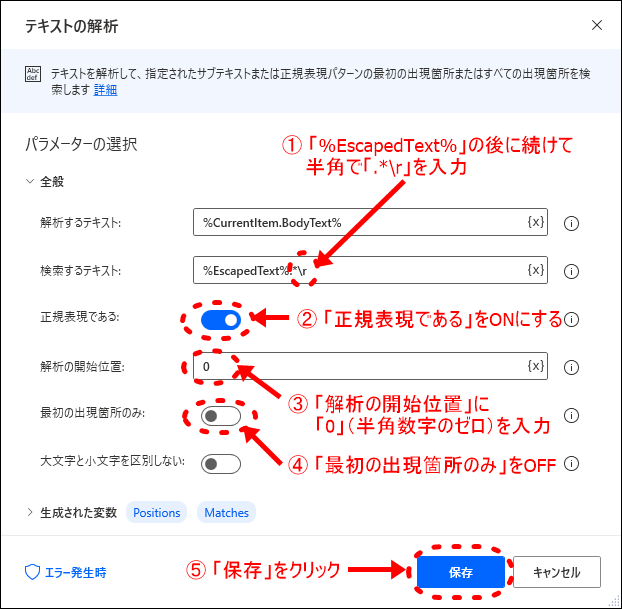
テキストを解析するための、その他の設定を追加して保存します。
- 「%EscapedText%」の後に半角で「.*\r」を追加入力します (※注「\」を入力しても画面上は「\」で表示されます)
- 検索には「正規表現」を使う
- メール本文の最初から解析する(解析の開始位置「0」から)
- メール本文には複数のURLが記載されるので「最初の出現箇所のみ」はOFF(ONだと最初のURLのみ抽出される)

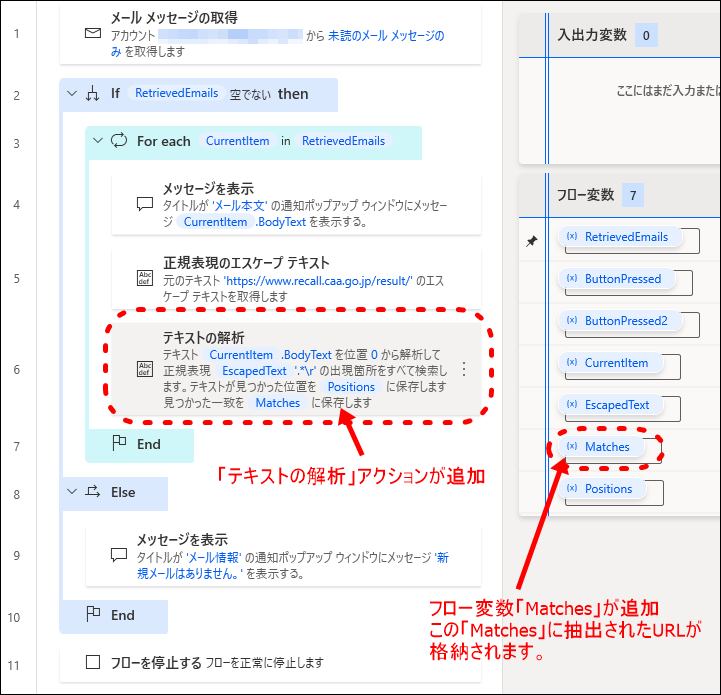
- 10「テキストの解析」アクションの追加を確認
「テキストの解析」アクションが追加されます。
「テキストの解析」アクションのコメントに記載されている通り、フロー変数「Matches」に、見つかった一致(今回の場合はリコール詳細情報のURL)が、リスト(配列)で格納されます。

完成したテキスト抽出フローの実行
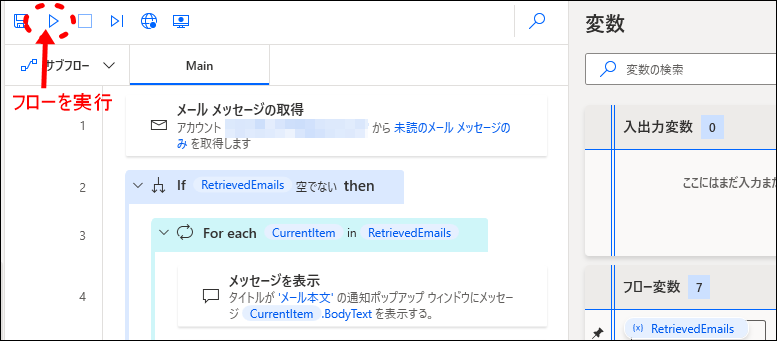
完成したフローを実行してみます。
- 1フローの開始
フローを開始します

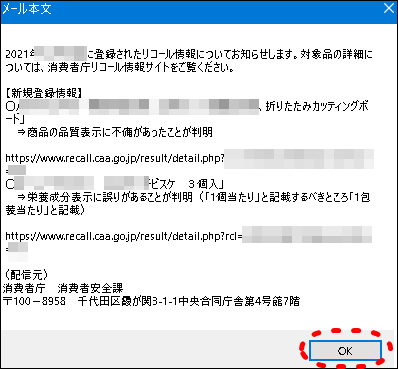
- 2メール本文のテキスト表示
まず新着リコール情報のメール本文テキストが表示されます。
今回追加したアクションにより、このメール本文からリコール詳細情報のURLのみを抽出します。
確認して「OK」をクリックします。

「OK」をクリックした後は、今回追加したアクションが順次実行されていきます。
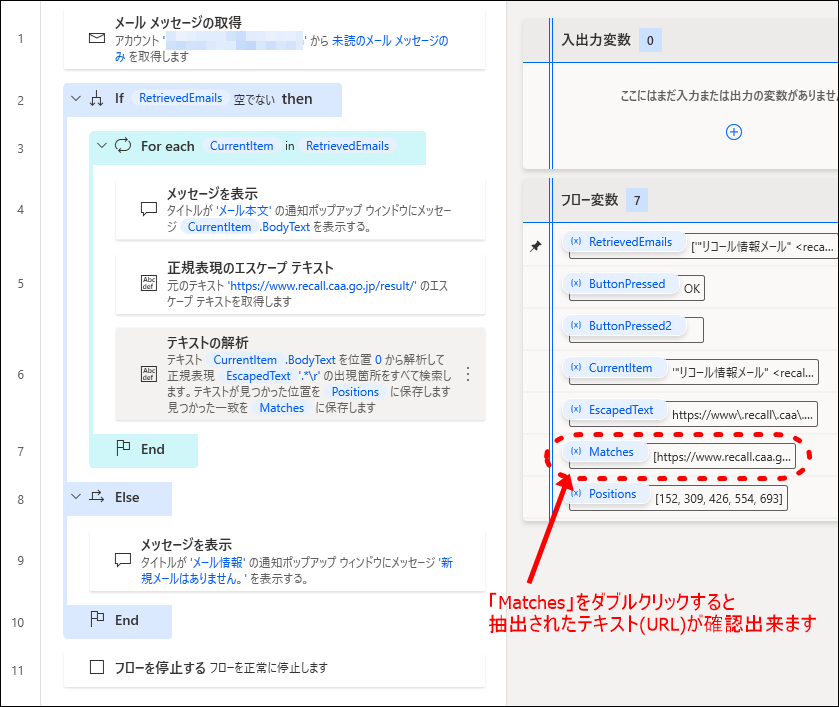
- 3フローの実行完了後にフロー変数「Matches」を確認
フローの実行が完了すると、フロー変数「Matches」にメール本文から抽出されたURLが格納されます。
「Matches」をダブルクリックすると、格納されている情報が確認できます。

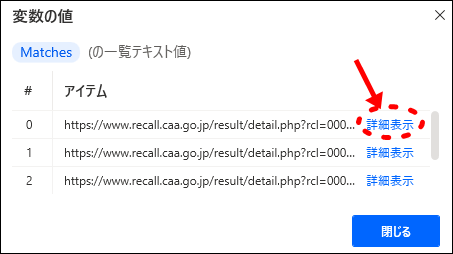
- 4「Matches」の詳細表示
「Matches」はリスト形式(配列)で複数のテキスト情報を格納しています。
メール本文にあったリコール情報の詳細ページURLが複数「Matches」に格納されているのが確認できます。
「詳細表示」をクリックすると、各URLが表示されます。

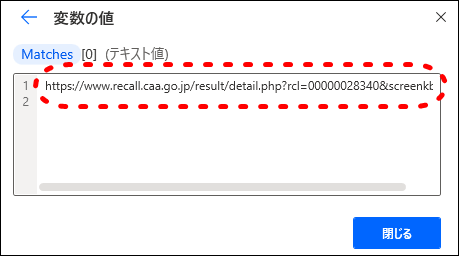
- 5抽出された各テキスト情報(URL)の詳細
抽出された各URLが確認できます。
このURLをブラウザで表示させると、リコール情報の詳細ページにアクセスできます。

以上で、メール本文から任意のテキストを抽出することが出来ました。
後日別の記事で、抽出したURLにアクセスし、そのページにある情報を取得するアクションを追加予定です。
Power Automate Desktopでのテキスト抽出と正規表現について
今回メール本文から任意のテキストを抽出するために「正規表現」を使いました。
「正規表現」を使うことで、URLのような複雑な文字列の組み合わせだけを抽出することが出来たりします。
RPAを使って自動化をするにあたって、何らかのテキスト情報を扱う必要がある場合、正規表現の利用方法を知っておくと自由度が格段に上がります。
Microsoft Power Automate Desktopで利用できる正規表現は「.NET」の正規表現になります。
「テキストの解析」アクションと正規表現を組み合わせることで、他にも様々なテキストから欲しい箇所のみを抽出することが可能になります。





